Entity Framework is pretty handy, but as we’ve seen before, you can sometimes end up with unexpected performance hits. This one took me by surprise a while back.
Let’s start with a simple Producs table in our database.
CREATE TABLE [dbo].[Products] (
[Id] [int] NOT NULL IDENTITY,
[Name] [nvarchar](max),
[Size] [nvarchar](max),
[Type] [int] NOT NULL,
CONSTRAINT [PK_dbo.Products] PRIMARY KEY ([Id])
)
Suppose we have a method to return the number of products:
public int GetProductCount()
{
var count = db.Products.Count();
return count;
}
No problem, right? Now, let’s say we want to be able to optionally filter the query to only include products of a certain type. We want this to be as fast as possible, so we’ll add an index to the Products table:
CREATE INDEX IDX_Products__Type
ON Products(Type)
INCLUDE (Id)
With the index in place, we’ll modify our GetProductCounts() method to support filtering on product type. We can do this easily by passing in a nullable int containing the product type to filter on, or null if we don’t want to do any filtering.
The simplest way to write this is to check if the type is null directly in the filter expression:
public int GetProductCount(int? type)
{
var count = db.Products.Count(p => type == null
|| p.Type == type.Value);
return count;
}
Still pretty straightforward, and it does exactly what you would expect.
Unfortunately, it turns out that calls to GetProductCount() are far, far slower than they should be. Why? To figure that out, we’ll have to take a look at the SQL captured by a SQL profiler after calling GetProductCount(2):
DECLARE @p__linq__0 int = 2,
@p__linq__1 int = 2;
SELECT
[GroupBy1].[A1] AS [C1]
FROM ( SELECT
COUNT(1) AS [A1]
FROM [dbo].[Products] AS [Extent1]
WHERE (@p__linq__0 IS NULL) OR ([Extent1].[Type] = @p__linq__1) OR (([Extent1].[Type] IS NULL) AND (@p__linq__1 IS NULL))
) AS [GroupBy1];
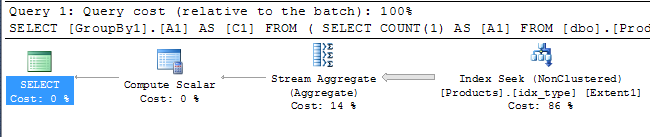
There are four separate conditions in the WHERE clause. This is due to the EF context’s UseDatabaseNullSemantics flag being set to false by default. Setting it to true reduces the WHERE clause to the two conditions you might expect, but it doesn’t actually solve the performance problem. Let’s have a look at the query execution plan to see what’s actually happening:

Yikes! It turns out we’re doing an index scan, not a seek. What effect does this have? A big one:
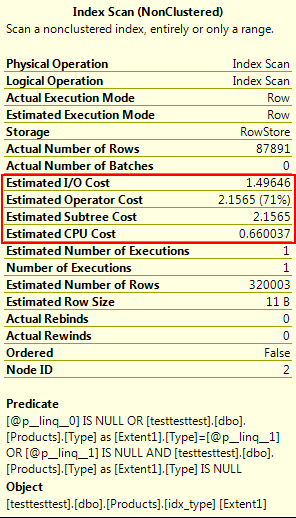
Fortunately, it’s easy to modify our code to work around this and eliminate the scan. We’ll remove the null check from the expression in the Count() method, and instead, check for a null type outside of the query. If the type isn’t null, we’ll add the where clause to the query.
{kind=link}
public int GetProductCount(int? type)
{
var query = db.Products.AsQueryable();
if(type != null)
query = query.Where(p => p.Type == type.Value);
var count = query.Count();
return count;
}
The generated SQL looks pretty good:
DECLARE @p__linq__0 int = 2;
SELECT
[GroupBy1].[A1] AS [C1]
FROM ( SELECT
COUNT(1) AS [A1]
FROM [dbo].[Products] AS [Extent1]
WHERE [Extent1].[Type] = @p__linq__0
) AS [GroupBy1];
And the query execution plan looks even better:
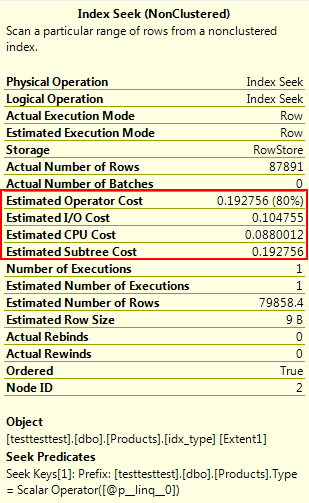
You can see that compared to the Index Scan above, the Index Seek is literally an order of magnitude cheaper:
Now, this simple SELECT COUNT query is fast enough in and of itself that the difference isn’t very noticeable. But if you have a bigger, more complicated query, it can have a huge impact – one query I dealt with went from ~1 second to ~30 seconds due to this issue.
In conclusion, be careful when using expressions with parameters in your queries! They might have unintended performance consequences.